MockK 오픈소스 기여: Kahn’s Algorithm으로 의존성 이슈 해결
매년 1월은 평소에 못했던 새로운 것을 시도해보는데 올해는 오픈소스 기여에 도전했습니다. 운이 좋게도 오픈소스 기여모임 10기에 참여해서 동기부여를 받으며 PR merge까지 마무리할 수 있었습니다. 이슈 선정과 분석, 해결 방식 등 오픈소스 기여 과정을 정리하고자 합니다.
오픈소스 및 이슈 선정하기
다음과 같은 기준으로 이번에 기여할 오픈소스 및 이슈를 선정했습니다.
1) 개발하면서 자주 사용했던 오픈소스에 기여할 것
2) 신규 기능이나 버그 수정에 기여할 것
단순히 Contributor가 되기 위한 작업보다는 평소 사용하던 오픈소스에 대한 감사를 표현하고 나도 참여했다는 성취감을 느끼기 위한 기여를 하고 싶었습니다. 그리고 문서 작성처럼 간단한 기여는 해본 경험이 있어서 이번에는 더 적극적인 기여를 해보자는 마음이었습니다.
회사에서 운영하는 서비스가 Kotlin, Spring 스택으로 개발 중이기 때문에 테스트 시에 MockK를 자주 사용했습니다. 그래서 관심 있게 살펴보던 중 해결이 필요한 신규 이슈를 발견할 수 있었습니다.
사실, 기여하기 좋은 이슈는 누군가 해결 중이어서 이슈 선정이 쉽지는 않았습니다. 제시하는 문제를 재현하고 이미 존재하는 해결책을 찾아서 공유하는 과정을 2~3번 겪은 후에야 기여할 이슈를 찾았습니다.
저는 비교적 클래식한 방법으로 이슈를 선정했지만, 오픈소스 기여모임에서 소개해준 Github 이슈 수집기와 AI를 활용한 이슈 분석 방식을 추천하고 싶습니다. AI를 활용하면 정말 수월하게 이슈를 분석하고 적절한 이슈를 추천받을 수 있습니다. 자세한 내용은 오픈소스 기여모임을 운영중이신 인제님의 포스팅(AI 활용 오픈소스 기여 가이드)에 상세하게 소개되어 있습니다.
이슈 분석: 의존성 초기화 순서 문제
제가 선정한 이슈를 요약하자면 여러 @InjectMockKs 프로퍼티 사이에 의존성이 있을 때 초기화 순서가 보장되지 않는다는 내용이었습니다. 이슈를 재현해보니 프로퍼티 명의 알파벳 순서에 따라서 초기화 순서가 결정되고 있었습니다. 이는 리플랙션으로 맴버 프로퍼티를 조회한 응답값 순서대로 Mock 객체를 초기화하기 때문입니다.
fun initMock(
target: Any,
overrideRecordPrivateCalls: Boolean,
relaxUnitFun: Boolean,
relaxed: Boolean,
) {
val cls = target::class
...
for (property in cls.memberProperties) {
property as KProperty1<Any, Any>
...
}
...
}
Kahn’s Algorithm으로 초기화 순서 정렬
Mock 객체 초기화 순서와 의존성 방향이 엇갈릴 때가 문제였기 때문에 개선 방향은 명확했습니다. @InjectMockKs 대상 객체와 그 사이의 의존성은 방향 그래프로 모델링 할 수 있기 때문에 위상 정렬(Topological sort)을 적용해서 이슈를 해결할 수 있었습니다.
위상 정렬을 구현하는 대표적인 방법으로 DFS 기반과 BFS 기반의 Kahn’s Algorithm이 있습니다. 두 알고리즘 모두 시간복잡도는 O(V+E)로 동일하지만, 다음과 같은 이유로 Kahn’s Algorithm을 선택했습니다.
| 구분 | Kahn’s Algorithm (BFS) | DFS |
|---|---|---|
| 구현 방식 | 반복문 (Iterative) | 재귀 (Recursive) |
| 순환 감지 | 처리 후 남은 노드로 자연스럽게 감지 | 별도 상태 관리 필요 (WHITE/GRAY/BLACK) |
| 스택 사용 | Queue 자료구조 (Heap) | JVM Call Stack |
| 디버깅 | 어느 노드에서 막혔는지 추적 용이 | 상대적으로 추적 어려움 |
선택 이유
1. 반복문 기반으로 스택 오버플로우 위험 감소
재귀 DFS는 그래프 깊이에 따라 JVM Call Stack을 사용합니다. 테스트 코드에서 생성되는 의존성 그래프의 깊이는 사용자 정의에 따라 제한이 없고, 특히 Android 환경처럼 스택 크기가 제한적이면 위험할 수 있습니다. Kahn’s Algorithm은 Queue를 사용하는 반복문 구조이므로 이런 걱정이 없습니다.
2. 명확한 순환 의존성 감지
Kahn's Algorithm은 in-degree가 0인 노드부터 처리하고 처리된 노드 수 < 전체 노드 수를 만족하면 순환이 존재한다고 판단할 수 있습니다. 별도의 순환 감지 로직 없이 알고리즘 결과만으로 MockKException을 던질 수 있어 구현이 단순해집니다.
반복문을 사용해서 DFS를 구현할 때도 순환 감지를 위한 상태 관리의 필요성이나 후위 순회 후 reverse 필요성과 같은 포인트에서 Kahn’s Algorithm이 유리하다고 판단했습니다.
JMH 벤치마크 성능 영향 검증
기능을 추가하며 의존성 Depth가 깊어진다면 오버헤드가 너무 커지지는 않을까 걱정이 되었습니다. 위상 정렬을 적용하면 기존 리플렉션 순회에 더해 그래프 구성과 정렬 과정이 추가되기 때문입니다. 이를 검증하기 위해 JMH를 사용하여 성능 테스트를 진행했습니다.
테스트는 다음의 4가지 케이스에 각각 의존성 개수(깊이) 5와 20을 적용하여 진행했습니다.
- independent: 각 객체가 서로 의존하지 않는 케이스
- wide: root가 여러개의 leaf들을 한꺼번에 의존하는 케이스
- linear: 선형으로 의존성 체인이 이어지는 케이스
- diamond: 의존성이 두 갈래로 분기했다가 다시 합쳐지는 다이아몬드 패턴이 반복되는 케이스
측정 결과 평균적으로 약 3-5%의 오버헤드가 발생했습니다. 절대적인 시간으로 보면 수십 마이크로초 수준의 차이라서 실제 테스트 실행 시간에 체감될 정도는 아니라고 판단했습니다. 위상 정렬의 시간복잡도가 O(V+E)이고, 일반적인 테스트 클래스에 의존성이 있는 Mock 개수가 많지 않다는 점을 고려하면 합리적인 수준입니다.
하지만 성능 저하가 존재하는 것은 사실이기 때문에 플래그 방식을 적용해야 할지 고민이었습니다. 그러던 중 때마침 메인테이너가 먼저 플래그 방식을 제안했습니다. 그래서 최종적으로 opt-in 플래그를 통해서 사용자가 필요한 경우에만 정렬을 적용하도록 수정했습니다.
@Before
fun setUp() = MockKAnnotations.init(this, useDependencyOrder = true)
PR Merge 및 후원
기능 구현 및 테스트 코드를 작성한 PR을 올린 후 메인테이너로부터 몇 가지 피드백을 받아 수정을 거쳤습니다. 벤치마크 결과를 첨부, 플래그 방식을 적용, README에 신규 기능 사용법을 문서화한 뒤 후 최종적으로 PR이 머지되었습니다. 그리고 제가 기여한 코드는 바로 지난주에 v1.14.9 버전으로 릴리즈 되었습니다.
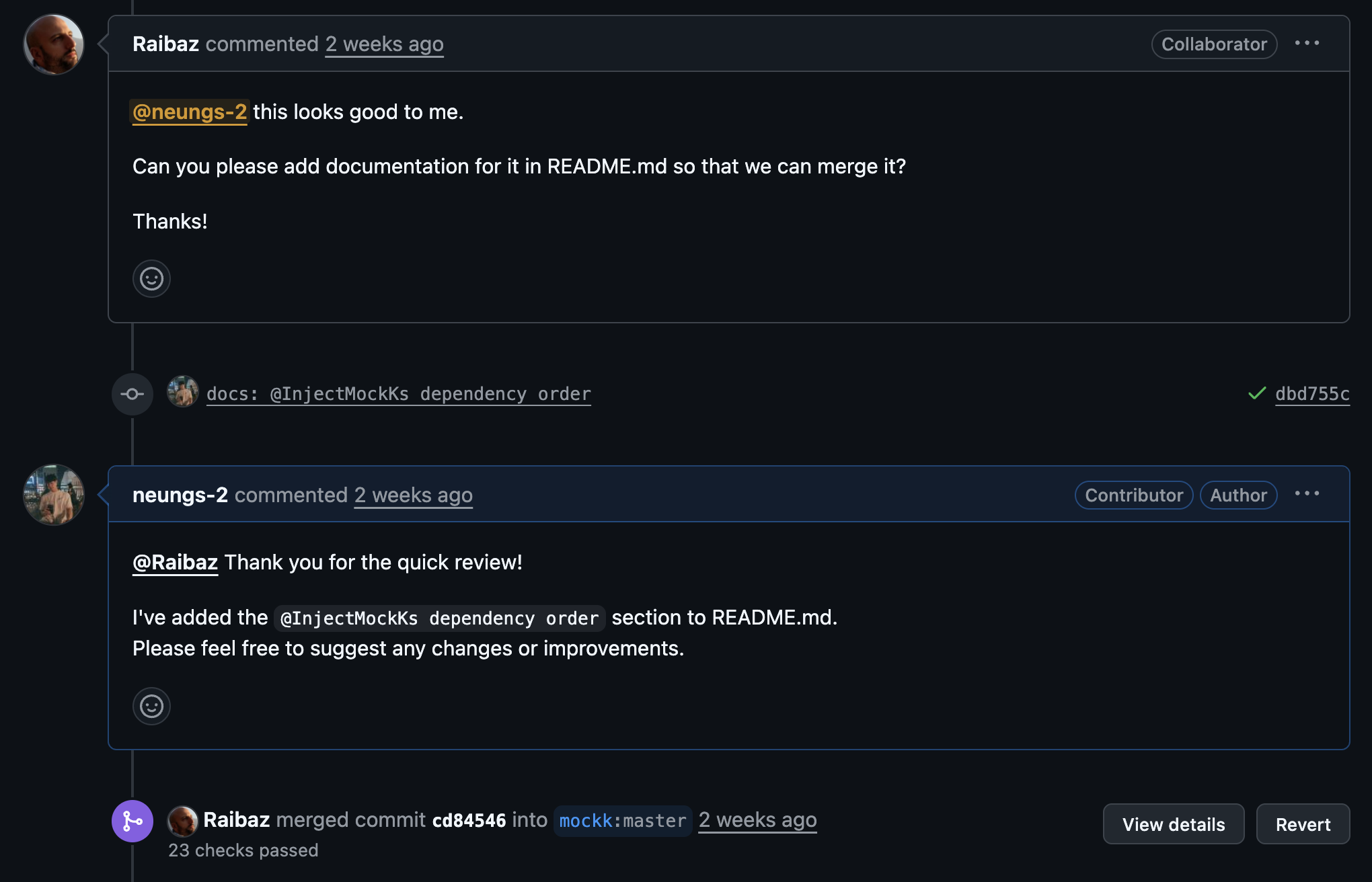
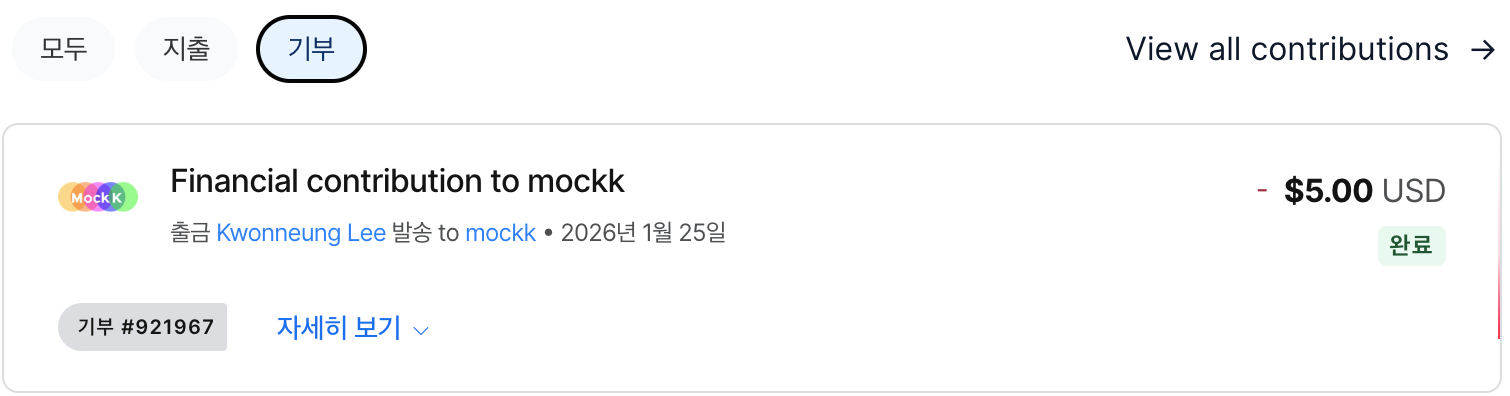
첫 feature 기여인만큼 의미가 있었고 동시에 내가 쓰고 있던 오픈소스들이 많은 사람들의 노력에 의해 운영된다는 점을 느낄 수 있었습니다. 오픈소스 기여모임에서는 Contribute뿐만 아니라 후원까지 독려하고 있습니다. 저도 감사의 마음을 담아서 MockK에 5달러를 후원했습니다.
후기
결과적으로 총 9개의 파일에 약 400줄 가량의 코드를 MockK에 기여할 수 있었습니다. 단순히 버그를 고치는 수준이 아니라 알고리즘 적용을 설계하고, 성능을 검증하고, 문서화까지 진행한 만큼 오픈소스 기여의 전체 사이클을 경험할 수 있었습니다. 무엇보다 제가 실무에서 매일 사용하던 라이브러리에 직접 기능을 추가했다는 점이 가장 뿌듯했습니다. 이번 기회를 계기로 더 많은 오픈소스에 꾸준히 기여해보려고 합니다.
처음 PR을 올릴 때에는 ‘내가 막 수정해도 되나…’ 싶은 맘이 들었지만 생각보다 오픈소스 생태계는 열려있으니 부담없이 도전해보면 좋을 것 같습니다. 혹은 도전해보고 싶지만 첫 시작이 망설여진다면 오픈소스 기여모임에 참여해보시는 것을 강력하게 추천드립니다!
댓글남기기